


Five-Minute Paper: AI vs. Vet Students
How well does ChatGPT stack up against DVM student knowledge?


Dear Readers,
Last year, ChatGPT made headlines when a study found it could pass the US Medical Licensing Exam (USMLE). That study, and others like it, led to excitement as well as anxiety about the possibility of AI replacing doctors and other knowledge workers. Soon after, much to the consternation of university faculty, many med students began using the software to help with coursework. I even played around with having it generate multiple choice questions to quiz vet students in a previous Substack post. An editorial in the New England Journal of Medicine described the disruption facing medical education:
“Medical schools face a dual challenge: they need to both teach students how to utilize AI in their practice and adapt to the emerging academic use of AI by students and faculty. Medical students are already starting to apply AI in their studying and learning, generating disease schema from chatbots and anticipating teaching points. Faculty are contemplating how AI can help them design courses and evaluations. The whole idea of a medical school curriculum built by humans is now in doubt: How will a medical school provide quality control for components of its curriculum that didn’t originate from a human mind? How can schools maintain academic standards if students use AI to complete assignments?”
To date, there has been minimal research on how ChatGPT and other AI tools may perform in a similar veterinary context… Until now! A new study published in JAVMA a few weeks ago evaluated two different OpenAI LLM models and how accurately they answered veterinary knowledge questions compared to third year veterinary students. This is the first study of its kind that I’m aware of, and provides important context about the capabilities of AI for veterinary medical knowledge.
—Eric

The Study:
Coleman MC, Moore JN. 2024. Two artificial intelligence models underperform on examinations in a veterinary curriculum. Journal of the American Veterinary Medical Association (published online ahead of print February 21, 2024).
Abstract
OBJECTIVE: Advancements in artificial intelligence (AI) and large language models have rapidly generated new possibilities for education and knowledge dissemination in various domains. Currently, our understanding of the knowledge of these models, such as ChatGPT, in the medical and veterinary sciences is in its nascent stage. Educators are faced with an urgent need to better understand these models in order to unleash student potential, promote responsible use, and align AI models with educational goals and learning objectives. The objectives of this study were to evaluate the knowledge level and consistency of responses of 2 platforms of ChatGPT, namely GPT-3.5 and GPT-4.0.
SAMPLE: A total of 495 multiple-choice and true/false questions from 15 courses used in the assessment of third-year veterinary students at a single veterinary institution were included in this study.
METHODS: The questions were manually entered 3 times into each platform, and answers were recorded. These answers were then compared against those provided by the faculty members coordinating the courses.
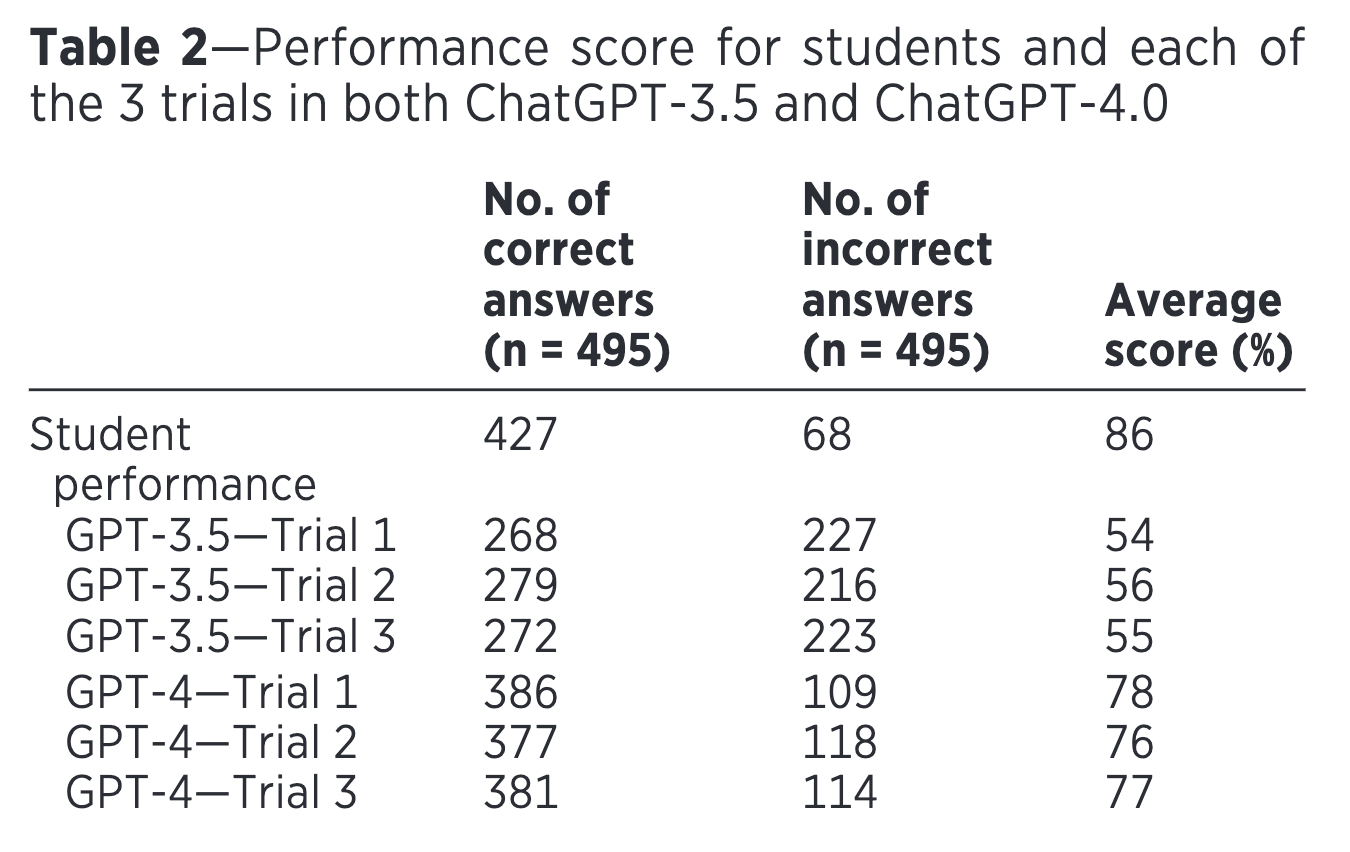
RESULTS: GPT-3.5 achieved an overall performance score of 55%, whereas GPT-4.0 had a significantly (P < .05) greater performance score of 77%. Importantly, the performance scores of both platforms were significantly (P < .05) below that of the veterinary students (86%).
CLINICAL RELEVANCE: Findings of this study suggested that veterinary educators and veterinary students retrieving information from these AI-based platforms should do so with caution.
What is this study about?
The study aimed to assess the knowledge level and consistency of responses of two versions of ChatGPT, GPT-3.5 and GPT-4.0, in comparison to third-year veterinary students.
Who did the research?
This study was performed by two faculty members at the University of Georgia College of Veterinary Medicine.
Who paid for it? Any conflicts of interest?
The authors reported no funding for this study and declared no conflicts of interest.
What did they do?
They collected 495 multiple-choice and true/false questions from 15 different courses:
Nine core courses—Large Animal Theriogenology, Large Animal Digestive Diseases, Musculoskeletal Disease and Pathology, Small Animal Digestive Diseases, Basic Surgical Techniques, Neurology, Cardiology, Respiratory Diseases, and Systemic Pathology II
Six elective courses taken by a select number of students—Small Animal Clinical Neurology, Small Animal Oncology, Small Animal Cardiology, Small Animal Advanced Anesthesia, Advanced Topics in Emergency and Critical Care, and Small Animal Musculoskeletal Diseases
The questions were entered into both ChatGPT platforms three times, and the answers were compared to those provided by faculty members. An example of the prompts can be seen in Table 1 below:

Results were analyzed by t-tests through commercial statistical software (SAS v9.4).
Here at All Science, we are on the PBS/NPR model: the vast majority of content is FREE, and paid subscriptions allow me to do the research and writing that goes into producing the site, as well as to give back to the community (donations to the Humane Society of Tampa Bay). If you find yourself enjoying these articles, consider becoming a free or paid subscriber 👇
What did they find?
The results showed that GPT-4.0 performed significantly better than GPT-3.5, with an overall performance score of 77% compared to 55% for GPT-3.5. However, both platforms scored significantly below the veterinary students' performance level of 86%. In terms of consistency, GPT-4.0 answered 69% of questions correctly across all three trials, while GPT-3.5 only answered 33% correctly across all trials.
“The performance scores of both [AI] platforms were significantly below that of the veterinary students”
What are the take-home messages?
This study highlights the mediocre performance of AI models in accurately representing knowledge in veterinary medical education, and suggests these LLMs are not yet ready for prime time. It does provide data to support that the paid GPT-4 is much more powerful and accurate than the free GPT-3.5 model. The authors discussed the implications of these findings, emphasizing the need for caution when using AI-based platforms for retrieving information. The study also discussed the importance of prompt engineering in obtaining optimal responses from AI models and highlighted the phenomenon of hallucinations, where AI may provide confident but incorrect answers.
Limitations of the study included the reliance on questions generated by faculty at a single institution and the fact that ChatGPT was trained on data before September 2021, potentially missing newer information. The study concluded by emphasizing the importance of critical evaluation and responsible implementation of AI tools in education, suggesting that AI should be used as a supplementary tool rather than a replacement for human expertise in medical and veterinary decision-making processes.
Hopefully, we will start seeing more research to help guide us on the best ways to use these powerful, but imperfect tools in veterinary education.
Well, the LLMs are still a work in progress, but the time is coming when their performance will outstrip human. The more the economic incentives the sooner that time will come. "What are people for?" is a question society should start looking intensely at. Right now.
Excellent article. I am interested in the effects of AI on our profession. By the way, I am sharing your article with my readers.