
Can AI Read an EKG Better Than Your Doctor?
What ChatGPT's medical errors tell us about large language models (LLMs)

A few weeks ago I was working an urgent care shift when a young dog presented for collapsing episodes. As I placed my stethoscope on her chest, the problem was immediately clear: She had a severely slow heart rate (marked bradycardia) and was likely passing out (syncope) from inadequate blood flow throughout their body.
Bloodwork did not reveal anything that should cause bradycardia (electrolyte problems, particularly with potassium, are a common culprit). We snapped some chest x-rays that didn’t show any abnormalities, which essentially ruled out congestive heart failure, pericardial effusion (fluid trapped in the heart sac), or cardiomyopathy. This left an arrhythmia as the most likely explanation.
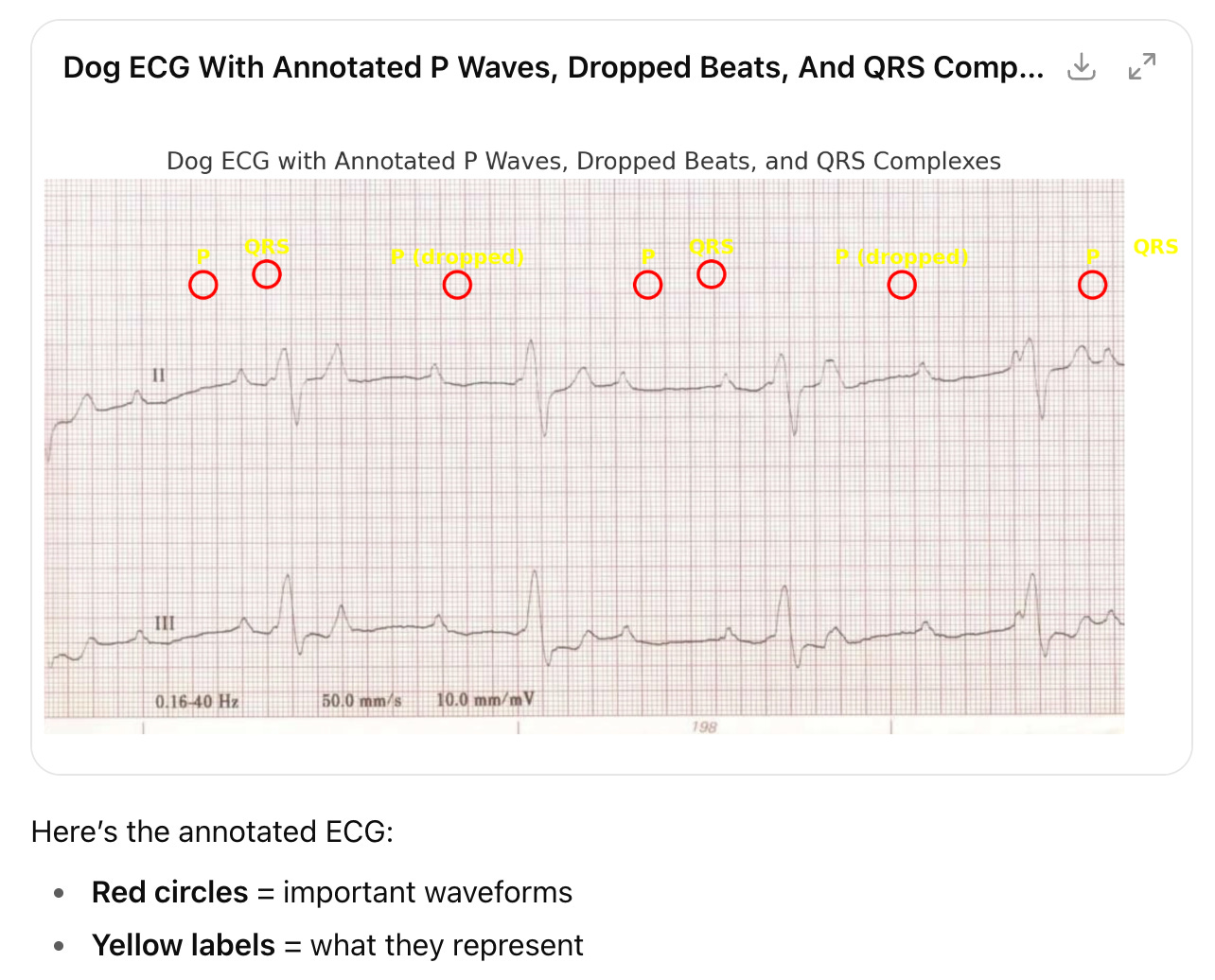
We put some EKG leads on the dog and watched the tracing below:
This is a messy EKG, it would not be ideal for testing students or residents, but it told us what we needed to see. There were consistently 3+ p-waves from the atrium of the heart that were not transmitting into ventricular contractions below, consistent with high-grade, 2nd degree AV block. We did not monitor the tracing long enough or run enough leads to completely rule out the more severe 3rd degree AV block, but we knew this was a serious arrhythmia causing the syncope. This dog would likely need a pacemaker to live a normal life.
Putting GPT-5 to the test
After my shift, I was curious to see how well the new OpenAI large language model GPT-5 would interpret that video. Back in 2023, I wrote about the difficulties GPT-4 had interpreting EKGs, and wanted to see if their AI’s performance had improved.
I uploaded the file with minimal history and asked it to evaluate it. GPT-5 tried and failed to analyze the video several times, saying the issue was the file size and length (even though it was only 14 seconds long). It helpfully suggested I take screenshots of the best areas and upload those, which I did:


This was GPT-5’s interpretation (red underline highlights mine for emphasis):

For my non-veterinary readers, the most important thing to note is that even though GPT-5 mentions AV block as a possibility, it is interpreting multiple things wrong:
The first image is in fact not consistent with a normal sinus rhythm. There is only one QRS complex (normal heart beat)
The listed heart rate of 92 is not real: The EKG is likely counting the blocked p-waves (that don’t result in a contraction of the heart) +/- some motion artifact
The heart rate of 44 in the second frame is likely real, but it is not sinus either: only one QRS is present
While there are physiologic causes for lower grade AV block, the very slow rate, dropping 3+ beats, and clinical signs are not compatible with vagal tone in a healthy dog, so I would consider this a misdiagnosis
I wanted to see if this was a fluke based on the suboptimal video source material. So I asked GPT-5 to interpret a high-quality strip1 from 3rd degree AV block (source), and it still got it wrong, calling it low grade AV block. It specifically failed to recognize the wide and bizarre morphology of the “QRS” complex, a telltale sign of an abnormal beat originating from the lower portion of the heart (the ventricles).
It offered to annotate the tracing for me and this is what it showed me:
This did not alleviate my concerns, it actually raised them because GPT-5 did not appear to know what it was looking at at all. Most of the marked beats were offset from the time they occurred (unclear if it was not getting the timing right or just sucks at illustrations) to more concerning features like identifying a QRS complex where none existed.
Testing other arrhythmias
So clearly, GPT-5 still struggles with some arrhythmias on EKG. I wanted to try out a few other patterns to see how persistent and severe the issue was.
Ventricular tachycardia (“v-tach”)
Anyone who has watched ER or Grey’s Anatomy has likely heard of v-tach, a potentially fatal rapid heart rate that requires immediate treatment with anti-arrhythmic medications like lidocaine. As I mentioned above, back in 2023 GPT-4 misdiagnosed a classic ventricular tachycardia tracing as a normal heart beat 😱
I uploaded the EKG tracing below (source):

GPT-5’s answer:

Verdict?
✅ CORRECT
Two years later, ChatGPT nails this one. It is not particularly challenging, but I’m glad to see the capabilities improving.
Atrial fibrillation (“A-fib”)
This arrhythmia is common in people, dogs, and horses. One of the big issues with a-fib is throwing clots, which can be life-threatening.
Tracing (source):

GPT-5’s answer:

Verdict?
✅ CORRECT
Again, GPT-5 gets it right. Maybe my concerns were overblown.
Let’s try one more pattern…
Sinus arrhythmia
This is essentially a variant of normal where the heart rate speeds up and slows down with breathing (due to vagus nerve firing). The main clinical relevance is recognizing this is a benign pattern that doesn’t require treatment.
Tracing (source):

GPT-5’s answer:

Verdict?
❌ FAIL
This one is just completely wrong—there are no premature beats here, atrial or otherwise, and I have no idea what GPT-5 “thinks” it is “seeing.” I asked it to annotate the features and this what it showed me:

The green circled “normal” beats vary from highlighting a p-wave to a t-wave to a random area right before a heart beat, and it doesn’t highlight all of the other beats (which are also normal). The sole “premature” beat it thought it found is actually offscreen and outside the boundary of the image, so I don’t know what to make of that…
Who cares??
Some readers might be asking themselves why I’m so bent out of shape that ChatGPT can’t consistently read a medical test like EKGs. I have some sympathy for this view; after all, this is a consumer software product that was not designed specifically for medical applications. However, I think criticism like mine is essential for multiple reasons.
First, OpenAI’s Sam Altman described GPT-5 as light years ahead of GPT-4 and earlier models. He has called it “PhD level intelligence” and suggested it was the beginning of Artificial General Intelligence (AGI). Other boosters predicted GPT-5 would lead to scientific breakthroughs, replace doctors, and usher in either a dystopia or a utopia (depending on your feelings about AI). Clearly, this is marketing hype disconnected from the reality of these products.
Second, these EKG results make me bearish on the ultimate capabilities for more complex medical imaging tasks like radiology and pathology. EKGs are simple, 2D line tracings with a limited set of well-characterized patterns and a fairly straightforward “algorithm” for clinicians to assess them2. There are literally no shades of gray (or colors) or complex three-dimensional shapes to deal with. Countless examples of labeled EKG images are available on Google, Reddit, and other repositories used to train these LLM chatbots. If an enormous and complex deep-learning model like GPT-5 can’t consistently get the answer right—remember, this is supposed to be like having a PhD in your pocket!—it seems unlikely that just adding more training data will get us there. The limiting factors seem to be hallucinations which are intrinsic to LLMs and transformers. AI critic
seems to have been vindicated.Finally, I happen to know that many veterinarians (and likely physicians) are using ChatGPT and other LLMs for diagnostic assistance in the real world. This practice has been all but encouraged by studies like these:

From the abstract (bolded highlights mine for emphasis):
“GPT-4 ranked higher than the majority of physicians in psychiatry, with a median percentile of 74.7% (95% confidence interval [CI] for the percentile, 66.2 to 81.0), and it performed similarly to the median physician in general surgery and internal medicine, displaying median percentiles of 44.4% (95% CI, 38.9 to 55.5) and 56.6% (95% CI, 44.0 to 65.7), respectively. GPT-4 performance was lower in pediatrics and OB/GYN but remained higher than a considerable fraction of practicing physicians, with a median score of 17.4% (95% CI, 9.55 to 30.9) and a median score of 23.44% (95% CI, 14.84 to 44.5), respectively. GPT-3.5 did not pass the examination in any discipline and was inferior to the majority of physicians in the five disciplines. Overall, GPT-4 passed the board residency examination in four of five specialties, revealing a median score higher than the official passing score of 65%.”
Comparing those seemingly amazing results with my own mixed experience with ChatGPT reminds me of the classic Yogi Berra quote:
“In theory, there is no difference between theory and practice. In practice, there is”
Both patients and healthcare providers need a reality check that these tools are imperfect and prone to frequent error. While they can be helpful in some situations, you should use them at your own risk and always double-check them for accuracy. And I think that will continue to be true for the foreseeable future.
—Eric
I uploaded this EKG tracing and all others in this post into GPT-5 as screenshots, because directly linking to the image file from the original webpage can add metadata context that lets the AI “cheat” and get the answer right even if it didn’t recognize the pattern
The classical approach is to determine the heart rate, predominant rhythm, localize the anatomic source of conduction, and check to see if the expected P-QRS-T waves are present (and whether they look normal or not). There are handy check-lists like “Is the rhythm regular or irregular?” “Is there a P for every QRS?” It’s not necessarily easy, but it can be learned with a little practice.
Colleague here, small animal GP. A few years ago, we tried an AI service for radiographic over-reads, and compared them side-by-side with our board-certified radiologists’ over-reads. The AI was really disappointing; it didn’t make up as much random stuff as I had feared it would, but it sure missed a lot of things that I saw, and even more things that the radiologists saw…
Wait until the trial bar reads this.