
Five-Minute Paper: Validating Radiology AI
Do these services live up to the hype??

Dear Readers,
I’ve written previously about the use of AI in veterinary pathology, radiology, cardiology, and more over the past few years. A lot of these articles were based on “anec-data” from personal experience, informed expert opinion, and limited proof-of-concept studies. Robust validation of these applications has been sorely lacking in vetmed, despite the fact that there are now many commercial services using AI to interpret x-rays, EKGs, blood smears, cytology, and urinalysis.
This is not a hypothetical discussion about a far-off future—veterinarians are employing these tools to make decisions about diagnosis, treatment, surgery, and euthanasia today. The question of whether or not these medical AI applications are accurate can be quite literally a matter of life and death, and we’re essentially flying blind. So when I saw that there was a brand-new study evaluating the performance of these systems published in JAVMA last week, I sat up and took notice.
Let’s dive into their findings in this edition of 5-Minute Paper!
The Study:
Ma D, Faulkner JE, Stander N, Raisis A, Joslyn S. Pilot study: external validation of commercial veterinary radiology artificial intelligence services shows deficiencies in interpretation of general practice-sourced canine abdominal radiographs.1 J Am Vet Med Assoc. 2026 Mar 20:1-8.
Abstract
Objective: To evaluate the diagnostic performance of commercial veterinary radiology AI platforms on general practice canine abdominal radiographs with confirmed diagnoses.
Methods: For this pilot study, canine abdominal radiographs with definitive diagnoses were collected and submitted to 6 AI platforms between September and December 2024. Confirmation of diagnosis was obtained with surgery, necropsy, CT, ultrasound, cytology, or treatment response when appropriate.
Results: 53 cases were selected and submitted to AI platforms. After platform rejections, 307 evaluations were available for analysis. When differentiating cases with pathology (51 of 53) and without pathology (2 of 53), platform performance was variable and mostly low to moderate, including mean accuracy (70% to 90%), balanced accuracy (60% to 65%), and Matthews correlation coefficient (-0.08 to 0.43). Across all platforms, classification of radiographic findings (labels) showed low sensitivity (28% to 78%), F1 score (28% to 51%), and positive predictive value (25% to 54%) due to frequent missed diagnoses. Matthews correlation coefficient was higher (0.16 to 0.45), as it was less impacted by label misclassification. Small intestinal obstruction, a critical finding, was often not identified, with a sensitivity of 23% to 69%.
Conclusions: Diagnostic performance varied between the 6 AI platforms tested and was overall low to moderate for this small sample. Even the best-performing algorithm had notable limitations, and none appeared suitable for clinical use in their current form.
Clinical relevance: Further independent external validations on a larger scale and performance gains are needed before AI platforms can be safely integrated into clinical practice.
What is this study about?
The authors compared the accuracy of six different veterinary radiology AI services to well-characterized cases with definitive diagnoses.
Who did the research?
Faculty at the Murdoch University School of Veterinary Medicine in Australia. Three of the authors are board-certified veterinary radiologists.
Who paid for it? Any conflicts of interest?
The study was funded by an intra-mural grant from Murdoch University. One author (SJ) owns a teleradiology service and a medical records system, which contributed case data to the study. No other authors reported disclosures, and none have a financial stake in any radiology AI companies. I deem the risk of financial bias to be very low.
What did they do?
This study pulled abdominal x-ray studies from retrospectively collected cases. Inclusion criteria were good-quality digital radiographic images with confirmation of a definitive diagnosis (by CT, surgery, autopsy, etc). They were reviewed blindly by one of the study radiologists, assigned a ground truth diagnostic label and classified as normal/abnormal and critical vs non-urgent. Then, they were anonymized, stripped of meta-data, and images were submitted as regular, paid cases to multiple AI services2. Importantly, the companies were not notified these were part of a research study (to reduce bias). They statistically compared cases at both a case level (true positives = abnormal ground truth, true negatives = normal ground truth, false positives = AI called abnormal but ground truth normal, and false negative = AI called normal but ground truth was abnormal) and a label-level (comparing specific diagnoses). Any cases rejected by an AI platform were excluded from calculating that service’s score, and for label-based assessment, they only evaluated diagnoses advertised by each company (to not penalize them for lesions outside their scope).
What did they find?
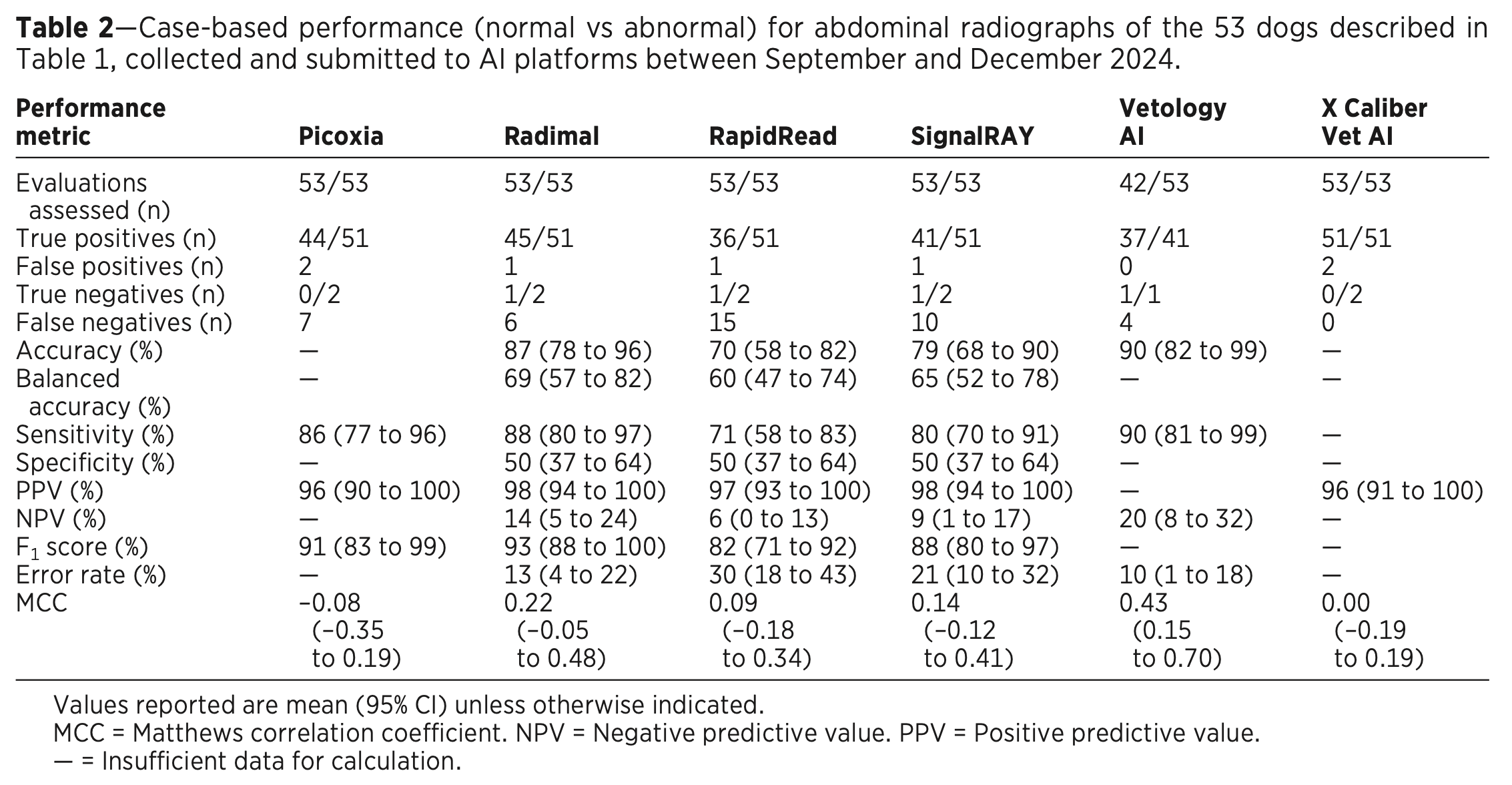
In total, 53 cases were included and submitted to the six AI services. Vetology rejected 11 cases (over 20%), all other services evaluated every case. At the simplest “case” level (binary call of normal or abnormal), sensitivity ranged from 71-90% (meaning 10-29% false negatives), and specificity and negative predictive values (NPV) were quite low for all. These results are summarized in Table 2:
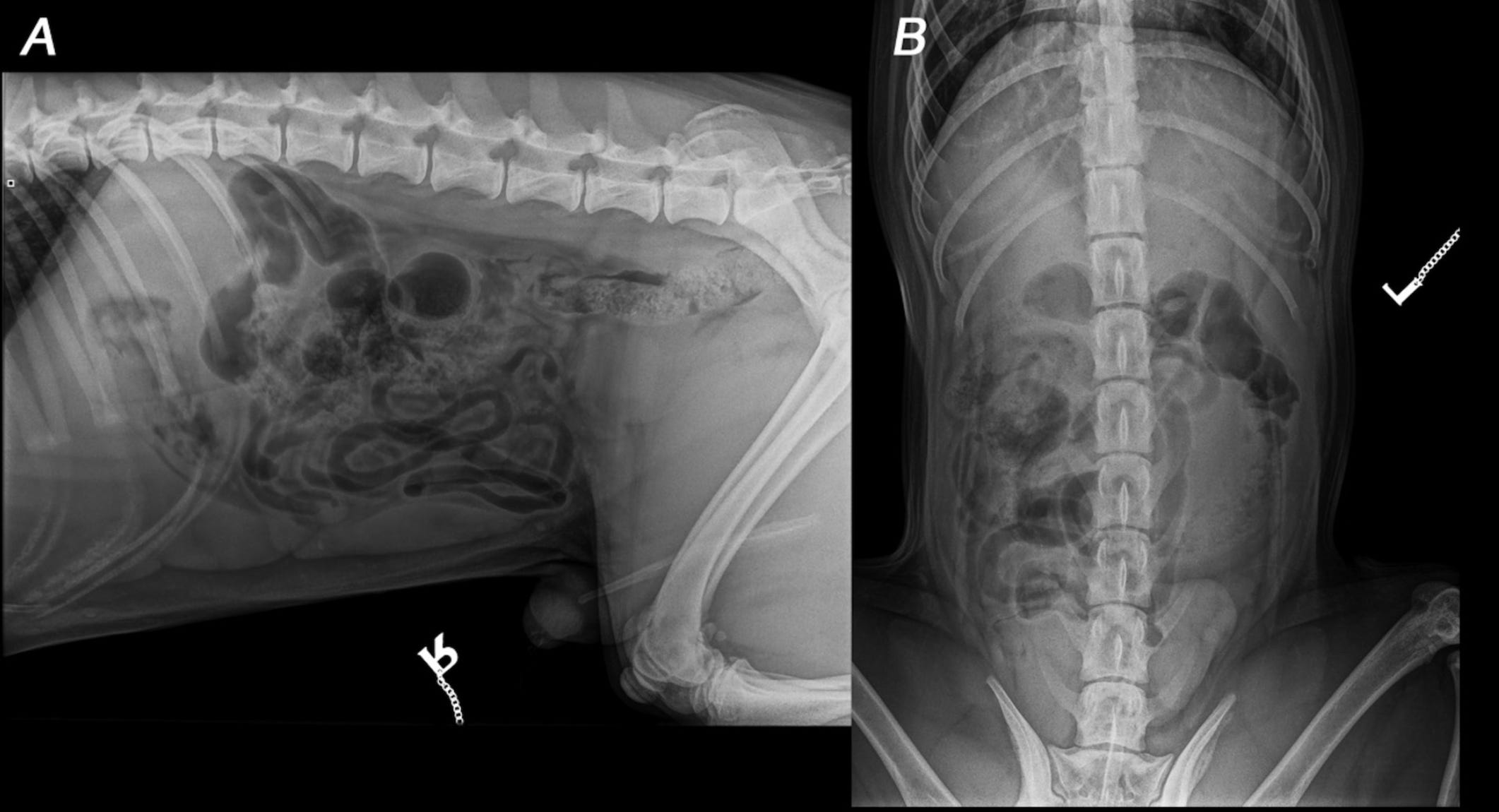
As you can probably imagine based on the “meh” (at best) topline numbers for just calling normal vs abnormal, the results for specific diagnoses were quite a bit worse. Sensitivity ranged from 28% to 78% for specific conditions, and was <50% for 5/6 companies. Perhaps unsurprisingly, the service with the highest sensitivity (X Caliber) also had the highest rate of false positive errors. You can see an example of this in the first half of Figure 2 below:
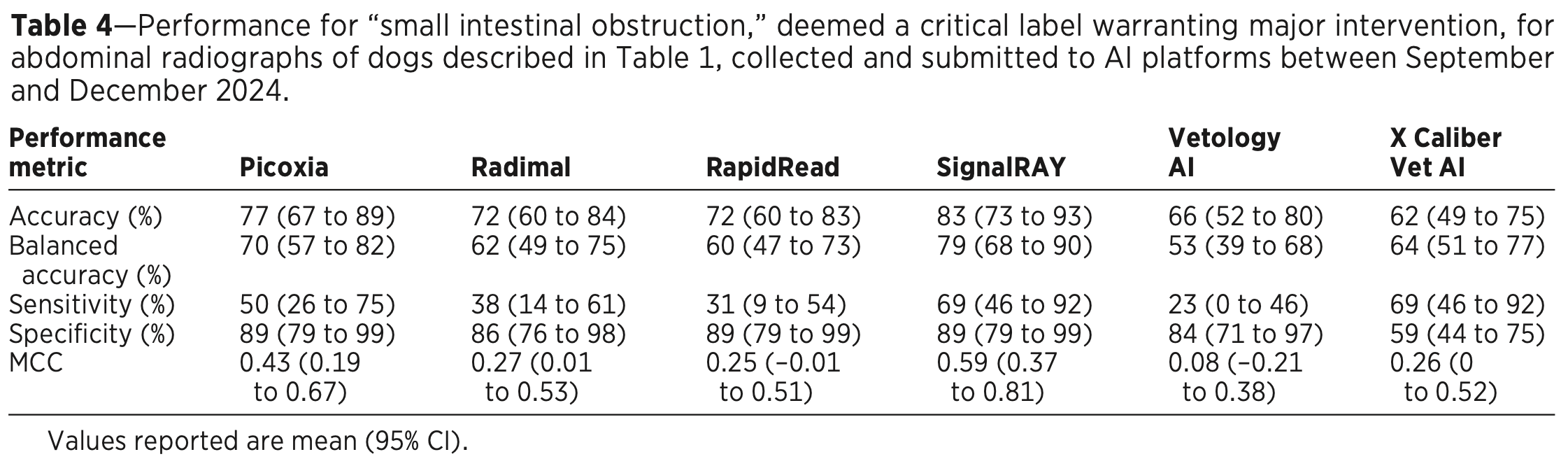
The results got truly scary when they zeroed in on specific urgent, life-threatening conditions like an intestinal obstruction (which requires immediate surgery). Sensitivity was poor across companies (23-69%), and none had an overall accuracy score in the 90s. See Table 4:
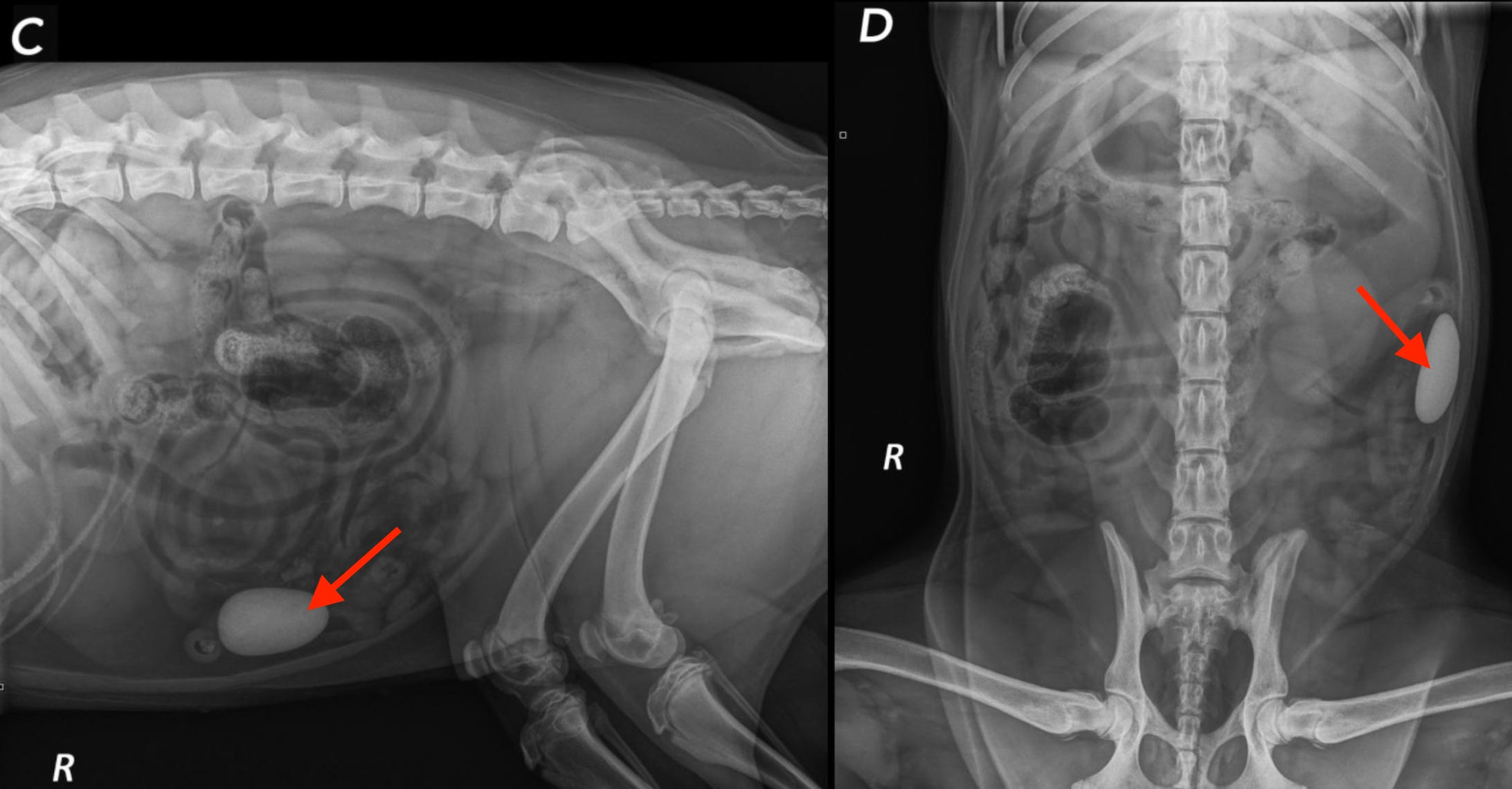
In what might be the craziest example, the authors showed a case where a dog literally ate a rock (red arrows), and one service called it NORMAL!!! Another went off the rails and diagnosed a bunch of crazy nonsense 😱
What are the take-home messages?
While this preliminary study is not without some limitations (primarily the small sample size and cases derived from a teaching hospital rather than general practice), it is to my knowledge the largest and most robust published evaluation of radiology AI services in veterinary medicine. As a study conducted by academics without a financial interest who took many steps to reduce possible bias, I find these results compelling—and disturbing.
The authors raise legitimate concerns about over-reliance on AI based on the poor performance for serious conditions like GI foreign bodies. They recommend general practice vets become educated about how these systems work and their limitations, and to always cross-check any outputs from the AI models. They also urge our profession to publish larger, prospective, multi-center trials of these systems, and for the companies building them to be far more transparent about their data, methods, and algorithm performance. Given the author’s conclusion in the abstract, it’s hard to disagree:
Even the best-performing algorithm had notable limitations, and none appeared suitable for clinical use in their current form
On a final note, believe it or not, but there is even less independent research of AI systems in pathology. Let’s hope that changes soon 🙏
—Eric
Author’s Note: The commentary above represents my personal opinion and does not necessarily reflect the viewpoints of any current or previous employers.
Note: this study is open-access, so everyone can read it!
Picoxia, Radimal, RapidRead (by Antech), SignalRAY (product of SignalPET company), Vetology AI, and X Caliber Vet AI.
Jesus Christmas. I cannot even with that
Interesting. I think there is good with use of AI but I just found out its quite imbedded in many hospitals particularly Palantir. The problem is it shows data and can solve some issues, but does it address critical staffing or is it more for efficiency of the hospital leaving out patients? Also notice Palantir has joined collectively with Joint Commission.